Le sujet des données est au cœur de toutes les entreprises. On peut répondre non à cette affirmation, mais en y réfléchissant bien, difficile de ne pas trouver d’activités où les données ne sont pas importantes quel que soit le contexte
Machine Learning : et si vous étiez prêt… sans le savoir ?

Données d’archives comme des plans, des schémas, mais aussi des données clients, des données de ventes, des mesures, des photos et tout ce que les entreprises conservent, classent.
Je peux donc revenir sur mon affirmation de départ : le sujet des données est au cœur de toutes les entreprises. Plus précisément, il l’est par la force des choses, sans même le vouloir, parce que les données générées sont très majoritairement conservées et représentent bien souvent la « mémoire de l’entreprise ».
De manière anarchique et empirique parfois, parce que leur « valeur » n’est pas visible. Ou de manière très structurée parce qu’il y a déjà un intérêt dans leur utilisation directe. Facturation, journal des ventes, fabrication, production ou autres.
Elles sont précieuses, parce qu’elles peuvent aussi et pour certaines être réutilisées pour générer de la valeur, elles peuvent (elles doivent) connaître une seconde vie !
Quelles données ?
Dans l’introduction, il est question de la réutilisation des données. C’est une réalité. Par exemple, un journal de ventes. Les données sont réutilisées dans leur cadre premier. Qu’ai-je vendu ces derniers jours (données qui ont été archivées / consignées) ? Combien ai-je vendu ce dernier mois en consolidant mes ventes du premier au dernier jour du mois ?
Ces données ont-elles de la valeur une fois que j’ai bouclé mon journal de ventes ? Oui.
Si je commence à les utiliser « hors contexte ». Pour essayer de prévoir mes ventes futures sur les données de ce dernier mois. Et par extension, pour déclencher l’approvisionnement en quantité suffisante sur les produits que je vends beaucoup. Et comme je sais qu’ils se vendent en quantité, je vais même « sur-approvisionner » avant que mon stock soit en danger, c’est-à-dire prévoir un « stock tampon » sur ces références. Efficace !
Efficace, mais pas toujours complétement exact. Je peux encore améliorer le modèle. En étendant la plage de mes données. Je vais cette fois utiliser les ventes sur l’année écoulée. Le modèle d’apprentissage est étendu, il me permet de voir que les ventes moyennes sont impactées par la saisonnalité, très fortement pour certains produits. De manière cyclique pour le matériel de ski qui connait une montée importante et régulière en termes de vente avant de connaître une chute brutale sans raison apparente. Ou plutôt de connaître une chute brutale tous les ans la dernière semaine des vacances scolaires d’hiver…
Mes données ont de la valeur et je peux, par des actions simples, dès aujourd’hui les enrichir pour qu’elles soient encore plus valorisables hors du contexte actuel. Parce qu’au-delà des cycles, il peut y avoir des situations exceptionnelles qui impactent mon activité. Je suis hôtelier, j’ai des pics de réservation dans l’année, en semaine, sur des courtes durées de 2 ou 3 jours. Et cela une quinzaine de fois dans tous les ans.
Incompréhensible !
…A la réflexion, il y a certainement un lien avec les salons professionnels qui se tiennent régulièrement à quelques kilomètres de mon hôtel. Je vais enrichir mes données d’historique. Date, Nombre de réservations, Météo, Vacances deviennent Date, Nb résa, Météo, Vacances, Salon.

Données enrichies par l’ajout d’une colonne Salon.
J’ai donné beaucoup plus de valeur à mon ensemble de données !
Cette longue introduction montre bien que vous avez dans votre environnement professionnel des sujets proches des exemples présentés. Et qui ont sûrement déjà fait l’objet de ce genre de réflexion de bon sens. Comment et par quoi mon activité a été positivement ou négativement impactée ? Comment grâce à ces données me préparer et prévoir au plus juste les semaines / mois / années à venir ?
On parle donc bien ici d’apprentissage (ou Learning) de données. Avec mon tableur, mes notes et mon historique je vais devenir « une machine à prévoir par l’apprentissage ».
A plus grande échelle, je vais m’appuyer sur des services Cloud spécialisés pour extraire et utiliser au mieux mes données.
Téléchargez cette ressource

Sécurité et gouvernance des applications d’IA
Les applications d’IA se multipliant dans les entreprises, ces dernières se doivent d’établir un cadre de gouvernance qui tient compte des risques de sécurité et des défis associés. Ce livre blanc vous offre les connaissances et les outils nécessaires à une gouvernance garante de la sécurité de vos applications d’IA.
Microsoft Azure Machine Learning
Microsoft Azure Machine Learning est un service PaaS dédié au Machine Learning. L’utilisation d’un service spécialisé permet de traiter et d’ingérer plus efficacement les données. Une remarque avant de passer à la pratique, les explications à venir ne se destinent pas à des experts de la Data Science, cette présentation pédagogique introduit le sujet du Machine Learning dans ses concepts de base.

La plateforme de services (PaaS) Microsoft Azure Machine Learning
Ce service est un ensemble de menus avec comme élément central le concepteur qui permet de réaliser des opérations de manière graphique avec peu de connaissances du sujet. La création des modèles prédictifs se fera sans code (il est tout de même possible d’en utiliser au besoin).
Concepteur graphique sans code, voilà une excellente manière de démarrer ce sujet.
Il y a plusieurs étapes pour concevoir et entrainer son modèle.
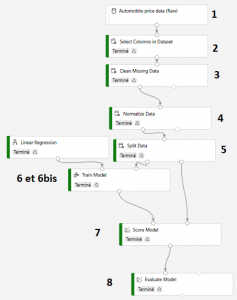
Concepteur graphique d’apprentissage machine (machine learning) en 8 étapes
Voici 8 étapes nécessaires pour bien démarrer !
1 / L’injection des données brutes (dont nous venons de parler plus haut).
2 / La sélection des données utilisées dans ces données brutes. Toutes les données d’une source de données ne sont pas forcément intéressantes à traiter.
3 / Le nettoyage des données qui feraient perdre de l’intérêt au jeu de donnés. Par exemple, l’absence de certaines données sur plusieurs lignes d’un tableau. Si les données sont trop incomplètes, il est parfois préférable de les nettoyer / supprimer avant utilisation. Plus les données sont cohérentes et complètes, plus elles permettront de prévoir au plus juste.
4 / La normalisation ou mise à l’échelle. Si dans le jeu de données, certaines colonnes sont à l’échelle 1 à 10 et d’autres, 100 à 10000, il faut mettre ces données à une même échelle, une échelle commune.
Ces 4 premières étapes sont simples à mettre en œuvre. Surtout, c’est votre expérience et la connaissance de vos données et de votre activité qui vont permettre de mettre en place un jeu de données pertinent. Ce sont ces étapes de filtrage et de sélection qui assurent une parfaite cohérence pour les étapes suivantes.
5 / Le split des données ou séparation des données d’entrainement et des données de test dans le jeu de données. L’objectif est d’entrainer le modèle sur une partie des données seulement et de conserver l’autre partie des données pour tester le modèle. Ainsi, l’échantillon de test est différent de l’échantillon d’entrainement. Cette séparation des données est clairement visible sur le concepteur.

Split Data ou séparation des données.
6 et 6 bis / L’entrainement du modèle et le choix de l’algorithme de traitement.
7 / L’étape Score Model est l’étape de prédiction qui se base sur le modèle entrainé par une partie du jeu de données appliqué à l’autre partie du jeu de données (Split de l’étape 5). Ici, l’échantillon de données de test donne un « score » à chaque donnée testée.
8 / L’étape d’évaluation est l’une des étapes la plus intéressante. C’est ici que la fiabilité du modèle est affichée et décortiqué ! Il n’existe pas d’algorithme générique permettant de traiter efficacement tous les types de données. Certains sont adaptés à un type de traitement, d’autres à d’autres types. Le service de Machine Learning expose donc les résultats et permet par des données chiffrées d’évaluer le modèle. Plus d’informations : ici
Pour aller plus loin et pour affiner les calculs, vous pouvez essayer un autre algorithme et comparer les résultats en connectant les mêmes sorties du module Split Data à un deuxième module Train model et à un module Score Model en connectant les sorties des deux modules Score Model au même module Evaluate Model qui permet d’effectuer une comparaison entre les deux modèles.
Plus facile à comprendre avec la vue du concepteur ci-dessous.

Calcul en cours pour deux modèles de régression linéaire avec des paramètres différents. Ces 2 modèles sont liés au même modèle d’évaluation pour comparaison.
Après plusieurs simulations et plusieurs évaluations, le modèle le plus performant va être publié. Il servira comme modèle de prédiction, comme simulateur d’activités futures.
Ce déploiement se fera en quelques clics !
Ce qui a été appris par les données passées permettra de mieux appréhender les données à venir.
Et la suite ?
Il a été question dans cette présentation de l’enrichissement des données dans la présentation théorique (Ajout d’une colonne « Salon »). C’est un point qui demande un peu plus d’explications.
Vos données d’entreprise auront encore plus de valeur si elles arrivent à être utilisées avec d’autres données, même des données qui ne vous appartiennent pas mais qui viennent d’autres sources et qui complètent le jeu existant.
Dans le rapport de la mission « Donner un sens à l’intelligence artificielle : pour une stratégie nationale et européenne » menée par Cédric Villani, il est question (entre autres) de l’accès aux données partagées ou données publiques =>
La révision prochaine de la directive sur la réutilisation des informations du secteur public doit être l’occasion d’accélérer le mouvement d’ouverture des données publiques et de préciser les modalités d’un accès à des données privées pour des motifs d’intérêt général.
Souhaitons que rapidement, ces données soient utilisables, partagées et permettent d’améliorer encore les données d’entreprise.
Voilà qui permettrait l’accélération des technologies d’apprentissage par la donnée.
Et maintenant, si vous vous posez de nouveau la question ? Etes-vous prêt sans le savoir ?
En résumé !
- Vos données ont de la valeur : ce n’est pas toujours visible, mais c’est très certainement le cas.
- Azure Machine Learning est un service PaaS de création des modèles prédictifs sans code : simple d’utilisation, c’est un très bon moyen de lancer un sujet Machine Learning.
- Les données prennent encore plus de valeur lorsqu’elles sont enrichies !
Les articles les plus consultés
A travers cette chaîne
A travers ITPro
Les plus consultés sur iTPro.fr
- Java fête ses 30 ans et se tourne vers l’avenir !
- IA : l’urgence de combler le fossé entre ambition et exécution
- Data center : l’efficacité énergétique au cœur de la révolution
- La recherche clinique boostée par l’IA et le cloud de confiance
- Plus d’identités machines que d’identités humaines en entreprise !









