La crainte de la panne est une réalité pour grand nombre d’entreprise. La question est toujours la même : Mais que va-t-il se passer si telle ou telle ressource présente une panne ? Jamais facile de répondre à cette question.
Azure Chaos, le choix de la panne

Pas que les choses soient mal ou non préparées, mais plutôt qu’il n’est jamais facile de simuler une panne et encore moins un ensemble de pannes. Et pas plus facile de trouver le temps et la manière de la provoquer pour voir si tout se déroule comme cela devrait se dérouler. Et ce même sur des opérations simples comme les tests de charge ou de performance.
Il est pourtant indiscutable que le test est un élément clef pour le SI. Il est préférable d’avoir une bonne vue d’ensemble de ce qu’il va se passer en cas de dysfonctionnements et a minima d’avoir une vision claire de ce que cela peut entrainer comme indisponibilité.
Attention, l’indisponibilité d’un système ou son fonctionnement en mode dégradé n’est pas toujours synonyme de catastrophe. C’est seulement lors des simulations que l’on pourra décider de ce qui demande plus de protection (résilience, redondance…etc) et ce qui est éventuellement acceptable. Se passer temporairement d’une application ou d’un service n’est pas toujours une hérésie. Dépenser sans compter pour augmenter la fiabilité n’est pas forcément la meilleure solution. Investir 10 pour ne pas perdre 5, une bonne idée ? Pas vraiment ou pas toujours à mon avis !
Avant de prendre la bonne décision, encore faut-il voir (simuler) ce que peut entrainer la défaillance d’un service ou d’un ensemble de services. Depuis peu, Microsoft a ajouté la fonctionnalité Azure Chaos dans le portail Azure. Elle permet de réaliser assez simplement ce genre d’opérations.
Du chaos dans le studio
Chaos Studio est un concepteur de simulation de chaos. Une console de création de scénarios de pannes ou d’indisponibilités. Cette fonctionnalité est en préversion et seules quelques régions sont pour l’instant éligibles. Pour l’Europe, North Europe et West Europe. France Central n’est pas encore déployée mais annoncée.
Présentation par l’exemple et avec quelques images de cette nouvelle possibilité
La première opération est le choix d’une cible sur laquelle vont être simulées les pannes. Soit au travers d’un service-direct (sans agent) pour l’ensemble des ressources soit au travers d’un agent pour les ressources de type VM et VMSS (Set de machines virtuelles). Premier point, même si le service-direct est possible sur les VM, ce n’est pas le meilleur choix. Son champ d’action est restreint et présente peu d’intérêt. La liste des possibilités de simulation est bien plus importante avec l’agent comme présenté sur l’écran suivant :
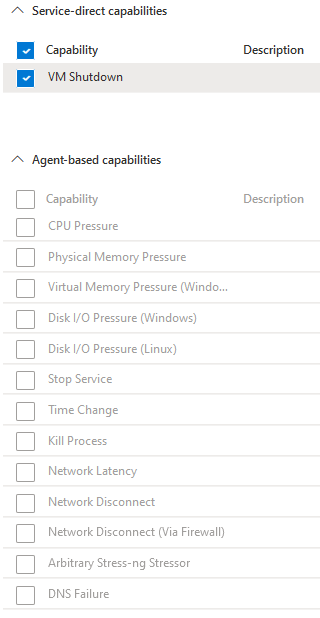
Une fois la ressource ajoutée en tant que cible, elle est éligible aux tests de pannes. Une ressource qui n’a pas été déclarée comme cible ne sera pas disponible dans la console et ne pourra être rattachée à une expérience de chaos.
Le studio est ensuite utilisé en mode expérience appelée Chaos Studio | Experiments. C’est ici que vont être empilées les actions. Des pannes ou des délais (Fault ou Delay dans le concepteur).
Avant d’ajouter les erreurs, il faudra parcourir la documentation éditeur que l’on retrouve dans une page « Bibliothèque d’erreurs et d’actions Chaos Studio » directement sur internet. Cette phase de documentation est indispensable. Certains tests n’ont besoin d’aucun prérequis, d’autres nécessitent l’installation d’un utilitaire complémentaire. Par exemple, l’action « Sollicitation de la mémoire physique » sur une machine Linux demande l’installation du package Stress-ng. Il n’y aura aucun prérequis pour ce même test sur une machine Windows. Il y a donc une phase d’étude préparatoire avant de bénéficier de l’ensemble des possibilités. Et une phase de déploiement d’outils complémentaires.
Puis viennent ensuite les paramètres de valeur des tests. Ce peut être un stress mémoire avec une sollicitation à 99%, du stress disque, un arrêt de process, une panne DNS ou même une latence ou une déconnexion réseau.
De la performance avec des pics de charge
De la performance donc, avec des pics de charge, mais également de la panne. Dans le détail, on voit dans le tableau suivant que les paramètres sont assez fins en termes de valeur. Ici, pour un stress sur différents modèles de disques Azure.

Cette phase préparatoire validée, les agents et outils installés, il ne reste qu’à créer une expérience. C’est-à-dire une suite d’actions et de pannes. Et choisir pour chaque faute la valeur des paramètres. Une durée pour une latence, un pourcentage pour un pic de charge, une non – réponse pour un service.
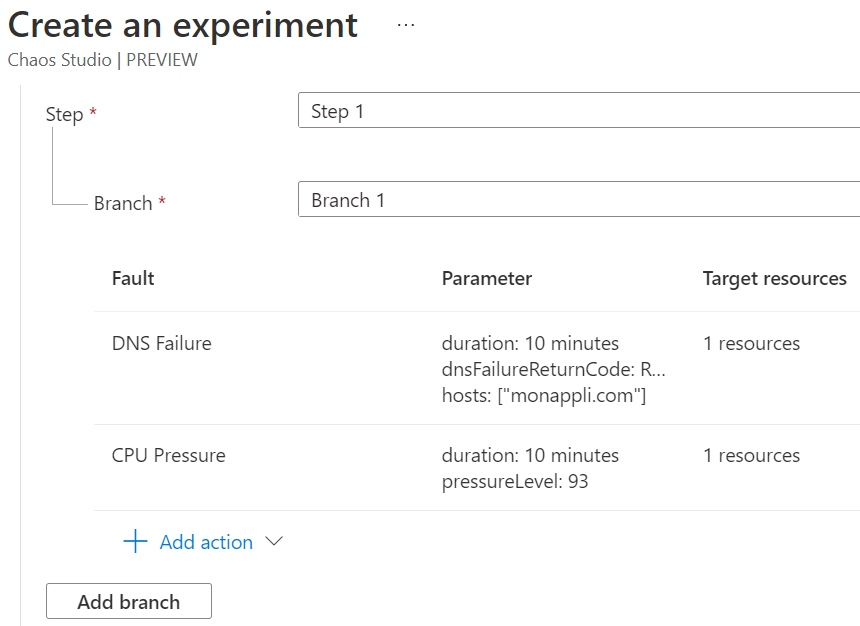
Il reste quelques étapes comme la création d’une identité qui aura les droits suffisants pour réaliser les opérations mais l’essentiel est là. Les différentes expériences sont réutilisables en modifiant les cibles (les ressources) qui sont à tester.
Présentée dans ce sujet sur une ressource de type machine virtuelle, la solution est bien plus complète et les ressources concernées sont variées.
De la machine virtuelle comme ce qui a été fait ci-dessus, de la base de données, de l’AKS …Etc. De quoi tirer de nombreux enseignements sur ce qu’entrainerait une panne sur un environnement Azure !
En Synthèse : un bon point de départ en 3 étapes
- Le studio Chaos est un simulateur de pannes pour les ressources Azure.
- La solution est utilisable avec ou sans agent.
- Les différents point de panne sont détaillés dans le document « Bibliothèque d’erreurs et d’actions Chaos Studio ».
Smart DSI N°27
Téléchargez cette ressource

Démocratiser l’adoption de l’IA par la maîtrise de ses données
Saviez-vous que 80% du temps de vos projets IA portent sur l’analyse de vos données ? explorez tous les outils nécessaires pour entreprendre une gestion performante de vos flux de données et optimiser votre architecture afin de réussir vos projets d’Intelligence Artificielle. découvrez le guide des experts Blueway.
Les articles les plus consultés
A travers cette chaîne
A travers ITPro
Les plus consultés sur iTPro.fr
- Télécommunications et durabilité : les défis d’une transition verte dans un secteur en mutation
- Vulnerability Operation Center : concepts, mise en œuvre et exploitation
- Faire face à l’évolution des cyberattaques : l’urgence d’une cybersécurité proactive
- Le temps où le RSSI était tenu pour seul responsable est révolu – la responsabilité incombe désormais à toute l’entreprise
- Le paradoxe de la sauvegarde : quand le sentiment de sécurité peut devenir une faiblesse









